基于單片機的智能終端中漢字顯示的處理

GB2312在此基礎上對矩陣進行劃分,分為94個區,每區94位,x定義了該字所在的行號,y表示該字所在的位號,x和y均以二進制或十六進制表示。這就是“區位碼”,例如:“啊”字的區位碼為(0x10,0x01),表示位于16區第一位。于是漢字庫中的字模存放位置(相對于字庫文件頭的偏移地址)可以由區位碼計算得到:偏移地址=區碼×94+位碼。那么“啊”字的字模相對于字庫文件頭的偏移地址等于16×94+1=1505(十進制表示)。
但是許多低位數字已被其它領域所占用,比如:0x06表示通信確認回答標志。為了不與已經存在的信碼相混淆,GB2312在每個區位碼上加上0x20,這樣形成的碼叫國標碼。例如:“啊”字的國標碼為(0x30,0x21)。
由于通用的ASCII字符的最高位為0,為了在計算機內部和之間傳輸漢字時可以和ASCII碼區別開來,將表示漢字的兩個字節的最高位都置1。這樣,相當于在國標碼基礎上高低字節同時加了0x80,這就是上面提到的內碼。比如:“啊”字的內碼為(0xB0,0xA1)。在計算機內部,用內碼來唯一標識一個漢字。在程序中,通過調用系統函數取得某個漢字的ASCII字符表示,也就得到了這個漢字的內碼。
在明白了內碼和區位碼之間的關系后,我們可以根據某個漢字的內碼計算得到該漢字的區位碼;再通過區位碼計算得到該漢字的字模在漢字庫表中的偏移地址;從此地址開始的連續32個字節就是該漢字的字模信息。
3.2 字模轉換
圖1中所示的漢字顯示與字模存放的關系是PC機中的字模存儲格式。而在單片機系統中,選擇不同的液晶驅動器要求有不同的字模存儲方式。比如我們在實際應用中,使用的是清華蓬遠科貿公司的HD61202液晶驅動器。圖5 指示了HD61202液晶驅動器所要求的字模存放與漢字顯示的關系。圖中標明了標出了第1、第2個字節和第31、第32個字節的存放位置。
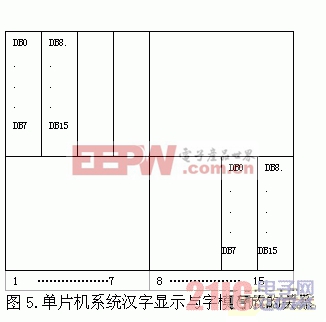
造成漢字顯示與字模存放有這樣關系是因為不同的液晶驅動器有不同的掃描顯示方式。所以,為了能夠將漢字正確的顯示出來,針對不同的液晶驅動要做相應的字模轉化。字模轉化可以自編一個轉化函數來實現,在寫入終端字庫下載文件前將32個字節的字模按位轉化為需要的格式,再按字節順序存入下載文件。
經過轉化之后,“大”字的字模(32個字節)變成:(32,32,32,32,32,32,160,127,0,64,64,32,16,12,3,0,160,32,32,32,32,48,32,0,1,6,8,16,32,96,32,0), 這就是存放在終端下載字庫中的字模格式。
參考資料:
1:《單片機應用系統設計》 何立民 北京航空航天大學出版社 1994
2:《漢字編碼標準與識別》







評論