基于FPGA的高速卷積硬件設計及實現

本文引用地址:http://www.j9360.com/article/148300.htm
為了在整個轉換計算過程中保持高信噪比,FFTIP核在定點結構與全浮點結構之間折中,使用塊浮點結構來表示轉換結果。在定點結構中,數據精度需要足夠大,才能充分表示整個計算過程中的所有的中間計算結果。在執行定點FFT過程中,經常出現數據的位數過大或精度損失的現象。而在浮點結構中,每個數用單獨的指數和尾數來表示,雖然這樣可以大大提高數據精度,但是浮點運算需要占用更多的器件資源。塊浮點結構保證了FFT整個轉換過程中數據位數的有效使用,每次通過基4-FFT運算以后,數據位數最大可能增加倍,根據前面輸出數據模塊動態范圍的測量進行比例換算,換算過程中累計的移位次數被作為整個模塊的指數輸出。這種移位方法保證了最低位(LSB)的最小值在乘法運算后的輸出進行舍入操作之前就被舍棄。實際上,塊浮點表示法起到了數字自動增益(AGC)的作用,為了在連續輸出模塊中產生統一的比例,必須用最終的指數對FFT函數輸出進行比例換算。
4 實際工程中的卷積的實現
如圖2所示,給出了一個實際應用的例子。為了保證I,Q兩路的相位同一性,使用雙通道A/D,選擇Linear公司的LTC2280,LTC2280支持10 bit,105 Ms/s的最大采樣率,并擁有61.6 dB的信噪比(SNR),85 dB的無雜散動態范圍(SFDR),滿足系統需要。雙通道D/A使用Analog公司的AD9763,AD9763支持10 bit、125 Ms/s的最大采樣率。
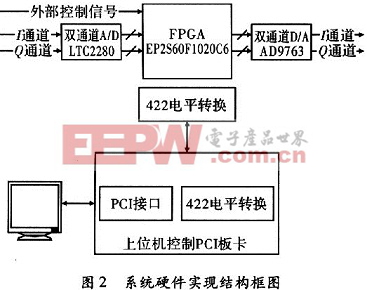
首先,需要在PC機上準備好h(n)對應的DFT變換結果H(k),H(k)的處理實際上有兩種方法,一個是將h(n)下載到下位機中,使用下位機硬件實現H(k),還有就是將H(k)在上位機就計算好,直接將計算結果下到下位機中。由于h(n)在系統工作中是不變的,在PC機端事先計算好H(k)更合適,不僅可以減少FPGA的資源占用,而且也方便數據的處理。基于以上的考慮,本系統將在PC機端求出的H(k)通過422接口下載到下位機的RAM中,方便使用。
下位機系統工作之前,上位機需要通過PCI控制板卡將計算好的數據下載到下位機的RAM中,方便工作過程中的數據使用。在收到外部控制信號后,下位機開始啟動,LTC2280開始采集I、Q通道數據并送入到FPGA中。
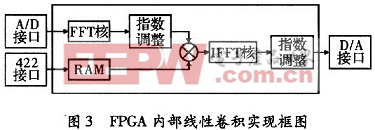
AD輸出的I,Q數據直接作為一個復數的實部和虛部進入FFT核進行FFT變換。為了加速處理速度,使用基-4四引擎輸出結構。FFT核輸出的結果X(k)過指數調整以后直接進入到一個硬件復數乘法器,與存儲于RAM中計算好的H(k)對應相乘,同時乘法器輸出可以直接輸入到IFFT模塊進行逆FFT運算,IFFT計算結果再經過指數調整以后即可以直接通過D/A輸出。
5 性能分析與改進
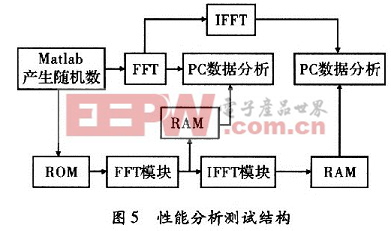
FPGA的流水線結構決定了速度的瓶頸取決于整個流程中處理速度最慢的部分。在FFT核速度可以保證的前提下(EP2S60的理論速度可以達到293.06 MHz),而處理過程中全部使用FPGA內部RAM來存儲中間數據,所以在本系統中,FPGA內部的理論處理速度達到200 MHz以上。本系統的處理速度主要局限于A/D和D/A的數據轉換率,根據實際測試,在100 MHz系統時鐘下,數據吞吐率可達100 Ms/s,滿足了設計技術指標。圖4給出了FPGA的資源占用。為了較好地檢測整個使用FFT_IFFT實現卷積的系統性能,設計了一個初略性能分析測試結構,如圖5所示。










評論